债务管理
搭建网站
BeanMap
htap
https
应届生就业
zookeeper
sklearn
医学
特征向量中心性
期末网页作业
自回归
xargs
paddlepaddle
学生HTML网页作业作品
一维高斯函数
TF-A
贵州茅台
测试员
卡顿
SGD
2024/4/12 3:13:26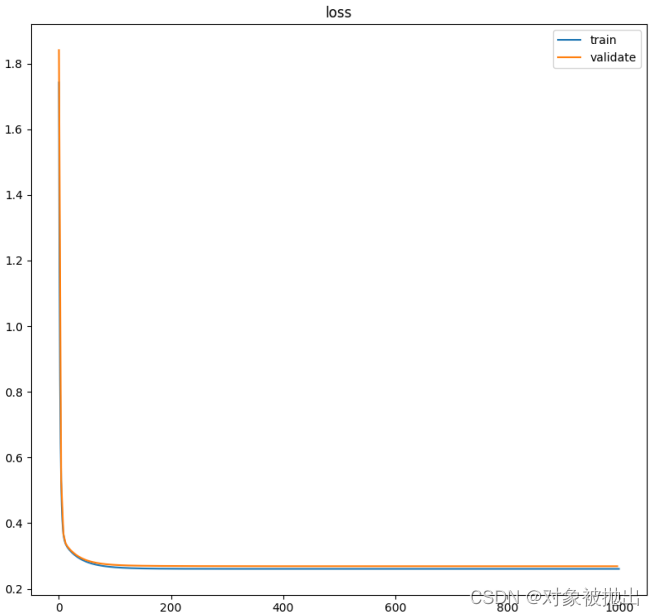
Python纯Numpy手撕SGD
文章目录简介问题建模数据加载和预处理数据加载预处理分batch损失函数训练运行简介
本博客用多元线性回归展示如何从零实现一个随机梯度下降SGD, 不使用torch等AI框架
问题建模
给定一个数据集X∈RN(D1)\large X \in \R^{N \times (D1)}X∈RN(D1)和对应标签向量Y∈RN\large …

深度学习常用优化算法
最早整理了一些深度学习的基础知识给实验室的师弟师妹看,后来想想还是写个博客大家一起看吧。 批量梯度下降法(Batch Gradient Descent) 在整个数据集上(求出损失函数 J(θ 并)对每个参数 θ 求目标函数 J(θ) 的偏导数…
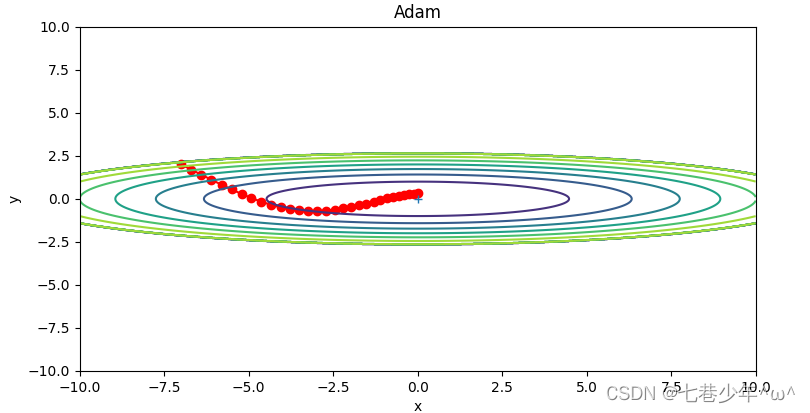
第五章.与学习相关技巧—参数更新的最优化方法(SGD,Momentum,AdaGrad,Adam)
第五章.与学习相关技巧 5.1 参数更新的最优化方法 神经网络学习的目的是找到使损失函数的值尽可能小的参数,这是寻找最优参数的问题,解决这个问题的过程称为最优化。很多深度学习框架都实现了各种最优化方法,比如Lasagne深度学习框架…

梯度下降与支持向量机
前言 支持向量机解优化有两种形式,通常采用序列最小化(SMO)算法来解优化,本文总结基于随机梯度下降(SGD)解优化方法。
线性可分SVM 如果数据集是完全线性可分的,可以构造最大硬间隔的线性可分支…

优化算法(一)SGD算法实现
SGD随机梯度下降算法,和最常用的GD相比,GD每一次迭代都是所有样本都一起进行计算,而SGD是每一次迭代中每个样本分别进行计算,梯度算法的最终目标是减少cost值,训练出最优的参数值,GD每一次迭代都让所有样本…

人工智能基础_机器学习014_BGD批量梯度下降公式更新_进一步推导_SGD随机梯度下降和MBGD小批量梯度下降公式进一步推导---人工智能工作笔记0054
然后我们先来看BGD批量梯度下降,可以看到这里,其实这个公式来源于
梯度下降的公式对吧,其实就是对原始梯度下降公式求偏导以后的梯度下降公式,然后
使用所有样本进行梯度下降得来的,可以看到* 1/n 其实就是求了一个平均数对吧.所有样本的平均数. 然后我们看,我们这里* 1/n那么…

优化器(Optimizer)介绍
Gradient Descent(Batch Gradient Descent,BGD)
梯度下降法是最原始,也是最基础的算法。
它将所有的数据集都载入,计算它们所有的梯度,然后执行决策。(即沿着梯度相反的方向更新权重ÿ…
Pytorch-SGD算法解析
关注B站可以观看更多实战教学视频:肆十二-的个人空间-肆十二-个人主页-哔哩哔哩视频 (bilibili.com) SGD,即随机梯度下降(Stochastic Gradient Descent),是机器学习中用于优化目标函数的迭代方法,特别是在处…

《python深度学习》笔记(十二):动量
1 工作原理
Momentum(动量,冲量):结合当前梯度与上一次更新信息,用于当前更新。
动量梯度下降法是计算梯度的指数加权平均数,并利用该数值来更新参数值。 指数加权平均: 与原始的梯度下降相比,动量的梯度…