参考:
- pytorch如何查看tensor和model在哪个GPU上
https://blog.csdn.net/weixin_37889356/article/details/121792888 - Part 3: Multi-GPU training with DDP (code walkthrough) [pytorch官方教程,有股咖喱味的Inglish, 推荐]
https://www.youtube.com/watch?v=-LAtx9Q6DA8&list=PL_lsbAsL_o2CSuhUhJIiW0IkdT5C2wGWj&index=5- 配套代码
- Tutorial page for this video →
https://bit.ly/3E219BM - Code used in this video →
https://bit.ly/3So1KSO
- Tutorial page for this video →
- 配套代码
- pytorch多GPU并行训练教程 [P导视频,虽然主讲launch启动,但是也有mp的方法,推荐]
https://www.bilibili.com/video/BV1yt4y1e7sZ/ - 34 多GPU训练实现【动手学深度学习v2】[李沐视频,主要讲了原理上手撸多GPU,没怎么涉及DDP]
https://www.bilibili.com/video/BV1MQ4y1R7Qg - facebookresearch/dino [facebook/meta 的知识蒸馏源码dino,使用了DDP,是一个很不错的demo,有对应的paper,推荐。TODO::写dino]
https://github.com/facebookresearch/dino - 上手Distributed Data Parallel的详尽教程 [了解一下backward()中的deduce其实是调用了barrier求平均来计算最终梯度的朝向]
https://zhuanlan.zhihu.com/p/486346821
目录:
- x.1 多GPU训练
- x.2 DDP原理
- x.3 DDP代码实践
- x.4 杂鱼碎碎念
- 如何查看model/net/模型在哪个GPU上
推荐阅读时间: 15min
x.1 前言
本文主要讲解的是Pytorch的多GPU训练,有多机多卡和单机多卡,本文主要讲解单机多卡。
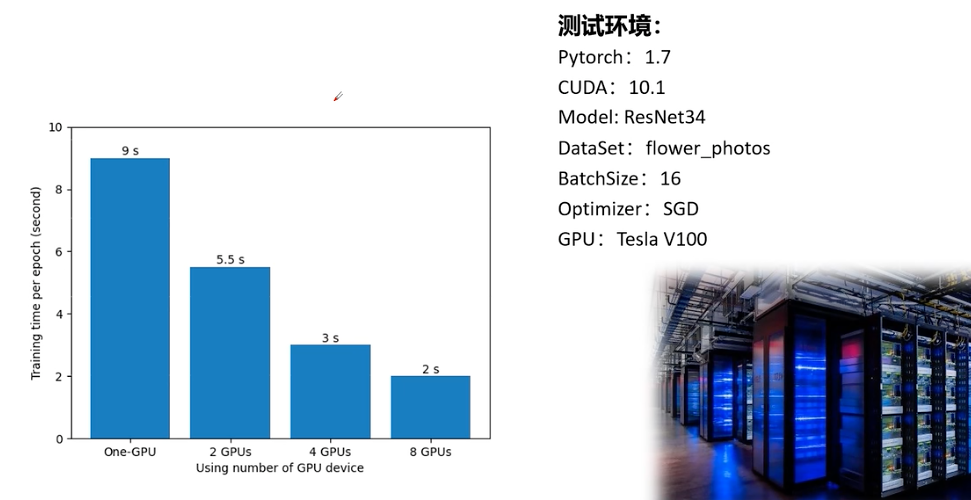
x.1.1 提升效果
使用GPU训练是为了提升收敛速度,batchsize大小等,以V100为例,提升效果如下(P导实验):
x.1.2 模型并行化和数据并行化
常见的多GPU训练分为model模型并行化和data数据并行化,本文主要讲解数据并行化。
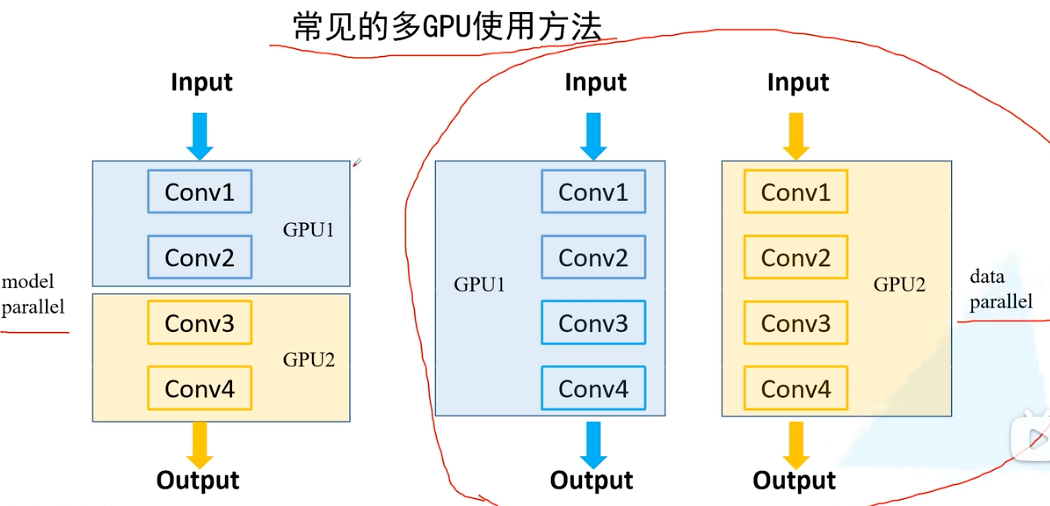
x.1.3 DP vs DDP
常用的多GPU训练方式有DataParallel(DP)和DistributedDataParallel(DDP)。DP是用在单进程多线程单机器的情况下,DDP可以用在多进程多机器的情况下,但是即使在单机上DDP的速度也大于DP的速度。

x.1.4 launch vs multiprocessing
常见的启动多GPU的方式如下,本文主要讲解多进程MP启动。

x.2 DDP原理
以数据并行化为例,在进行多GPU训练时,我们需要考虑问题有GPU如何初始化,数据集如何在不同设备间分配,误差梯度如何在不同设备间通信(通信后需要一个求平均的操作),BatchNormalization如何在不同设备间同步,而这些问题DDP都已经很好的封装成了函数。
x.3 DDP代码实践
在代码实践部分,我们将DDP的原理可以提取为以下几个步骤DDP多进程初始化,数据集切割和分配,学习率的倍增和loss.backward()传递,权重加载(每次在第0张显卡存储权重参数),将模型转为DDP模型,BN在设备间的通信,训练。
x.3.1 DDP多进程初始化
x.3.1.1 用多进程启DDP
mp.Process vs mp.spawn 在使用DDP时,其实本质上起了多个进程,每个进程控制一个GPU的运行,常见的启动多进程的方法有torch.multiprocessing中的spawn和Process,在这里使用的是Process,Process起进程会比spawn快几秒。
在使用mp.Process启动的进程代码需要传参:
- rank:当前GPU的id
- world_size:总共GPU的数量
- dist_url:dist_url是指分布式训练过程中用于建立进程间通信的URL。它通常用于指定分布式训练的后端,例如TCP、文件系统等,具体可以看
碎碎念中内容x.4.2,这里指定为env:// - dist_backend:dist_backend是指用于执行分布式训练的后端实现。它定义了在分布式训练期间如何进行进程间通信和同步,具体可以看
碎碎念中内容x.4.3,这里指定为nccl - device_str:默认指定为
cuda,别更改。
使用mp启动的代码如下:
from torch.multiprocessing import Process # mp.Process vs mp.spawn
processes = []
for rank in args.gpu_ids:
p = Process(target=run_ddp, args=(rank, world_size, args.dist_url, args.dist_backend, args.device_str))
p.start()
processes.append(p)
for p in processes:
p.join()
# 使用mp启动
# when using mp.spawn, if I set number of works greater 1,
# before each epoch training and validation will wait about 10 seconds
# import torch.multiprocessing as mp
# mp.spawn(main_fun,
# args=(opt.world_size, opt),
# nprocs=opt.world_size,
# join=True)
x.3.1.2 在单个进程中配置单个GPU参数
- 指定环境变量
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = "12355"
首先我们需要指定环境变量os.environ["MASTER_ADDR"]和os.environ["MASTER_PORT"]。设置了用于通信的主节点地址和端口号。在本示例中,主节点地址被设置为本地主机(localhost),端口号为12355。这些信息将用于初始化分布式进程组。
- 设置CUDA设备
torch.cuda.set_device(rank)
这行代码将当前进程的CUDA设备设置为与进程的rank相对应的设备。这是为了确保每个进程使用不同的GPU设备进行计算。
- 初始化分布式进程组
torch.distributed.dist.init_process_group(backend=dist_backend, init_method=dist_url,
world_size=world_size, rank=rank)
调用了dist.init_process_group()函数来初始化分布式进程组。它需要提供一些参数,包括backend表示分布式后端的类型(如NCCL、Gloo等),init_method表示初始化方法(通常是一个URL或文件路径),world_size表示总共的进程数,rank表示当前进程的排名。
代码如下:
# --- |
# --- | 1. init GPUs | ---
# --- |
# 初始化各进程环境 start
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = "12355"
torch.cuda.set_device(rank)
print('| distributed init (rank {}): {}'.format(
rank, dist_url), flush=True)
trainer.multi_train_utils.distributed_utils.dist.init_process_group(backend=dist_backend, init_method=dist_url,
world_size=world_size, rank=rank)
trainer.multi_train_utils.distributed_utils.dist.barrier()
# 初始化各进程环境 end
其中torch.distributed.dist.barrier()函数用于进程同步。它会阻塞进程,直到所有进程都调用了该函数才会继续执行。这可以确保所有进程在开始执行后的某个点上同步。
x.3.2 数据集切割和分配
x.3.2.1 DistributedSampler用于分配数据
DistributedSampler用于给每个rank对应的进程分配训练的样本索引。如下图所示:试着将11个样本分配在两个GPU上,会先Shuffle数据,由于无法整除会在增加一个数据,再将最终生成的12个数据进行分配:
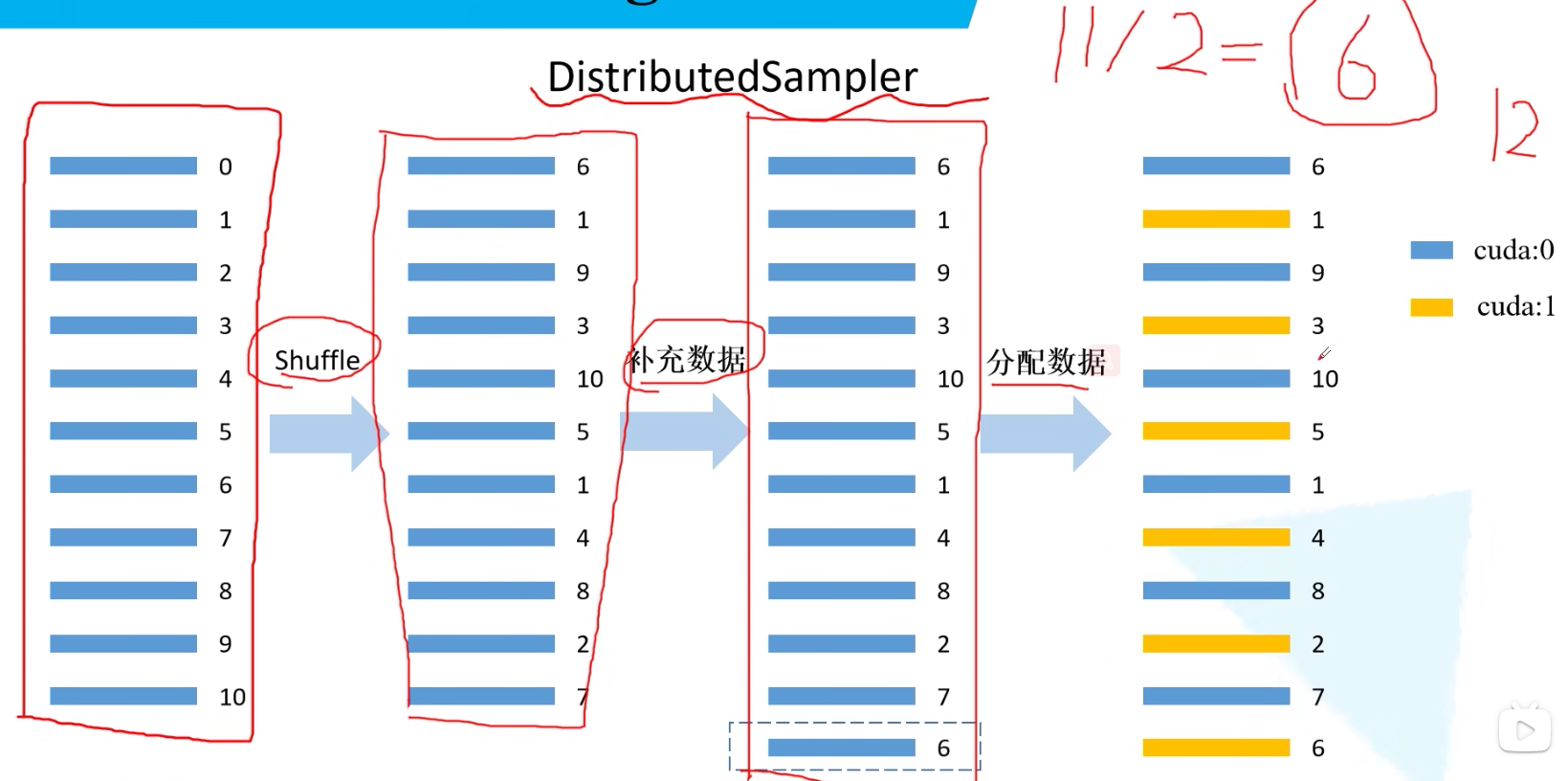
案例代码如下:
train_sampler = torch.utils.data.distributed.DistributedSampler(train_data_set)
val_sampler = torch.utils.data.distributed.DistributedSampler(val_data_set)
这两行代码创建了分布式采样器对象,用于在分布式训练中为每个进程分配对应的训练样本索引。train_data_set和val_data_set是训练集和验证集的数据集对象。这样做可以确保每个进程在训练时只处理分配给它的样本。
x.3.2.2 BatchSampler将样本索引每batch_size个元素组成一个列表 (可选)
如下图所示,序号为6,9,10,1,8,7的sample在DistributedSampler()方法后传入cuda:0中,若batch_size=2,则在BatchSampler中每次取2个batch;若为batch_size=4还可以设置多余的数据丢掉。
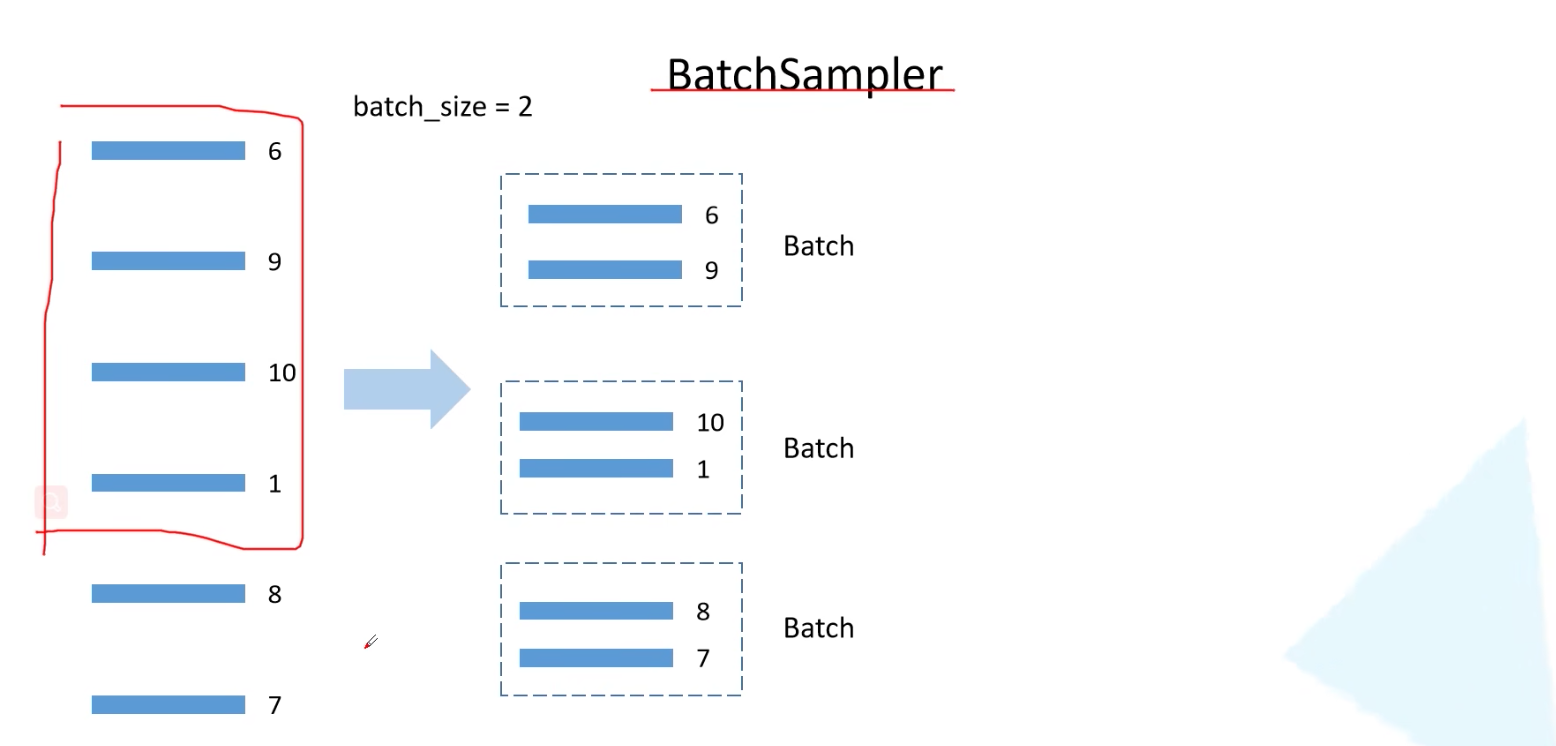
代码如下:
train_batch_sampler = torch.utils.data.BatchSampler(train_sampler, args.batch_size, drop_last=True)
这行代码创建了一个BatchSampler对象,用于将训练样本索引按照指定的batch_size划分成多个批次。train_sampler是之前创建的训练集的分布式采样器对象,args.batch_size表示每个批次的样本数量,drop_last=True表示如果最后一个批次的样本数量不足batch_size,则丢弃该批次。
在这里,我们只将训练集的数据分为batch_size传入,而并没有将验证集划分为batch_size。其实只有DistributedSample是必须的,而BatchSampler并不是必须的,可以参考x.4.5 DistributedSampler和BatchSampler搭配使用
x.3.3 学习率的倍增和loss.backward()传递
学习率的倍增 在学习率的使用中,由于每次并行计算的是多个GPU上的梯度方向的平均,所以需要将学习率倍增才能得到应有的前进的长度,如下图:
代码如下:
args.lr *= world_size # 学习率要根据并行GPU的数量进行倍增
loss.backward()传递 那么在6张GPU上会计算6个梯度方向,那根据6个梯度方向是如何确定最终的梯度方向以及最后的loss值的呢,其实这一切都封装在了loss.backward()函数中,参考https://zhuanlan.zhihu.com/p/486346821中有这样一段话:

这也解释了不同设备间的loss如何通信,其实都封装在loss.backward()中了。
x.3.4 权重加载(每次在第0张显卡存储权重参数)
如果预训练权重存在则加载预训练权重;
如果不存在预训练权重参数则加载使用rank0的GPU初始化权重后保存(注意要使用model.module.state_dict()保存参数,详见x.4.4 在DDP中为何要使用model.module.state_dict()保存模型参数),barrier()后再加载rank0保存的模型参数。
这里注意,一定要指定map_location参数为各自的GPU rank,否则会导致第一块GPU占用更多资源。
x.3.5 将模型转为DDP模型
使用torch.nn.parallel.DistributedDataParallel(model, rank)函数将模型封装成DDP模型并运行,案例代码如下:
# 转为DDP模型
gpu_id = trainer.multi_train_utils.distributed_utils.dist.get_rank()
resnet_trainer.net = torch.nn.parallel.DistributedDataParallel(resnet_trainer.net, device_ids=[gpu_id])
这段代码是将模型转换为DDP(分布式数据并行)模型的过程。
首先,使用trainer.multi_train_utils.distributed_utils.dist.get_rank()获取当前进程的GPU ID。dist.get_rank()函数返回当前进程在分布式训练中的排名。
然后,将模型resnet_trainer.net封装到torch.nn.parallel.DistributedDataParallel中,以创建DDP模型。DistributedDataParallel会复制模型到多个GPU设备上进行并行计算。
在这里,通过传递device_ids=[gpu_id]参数,指定该DDP模型仅在当前GPU设备上运行,而不是在所有可用的GPU设备上运行。这样做是为了确保每个进程只在其分配的GPU设备上运行。
综上所述,这段代码的作用是将模型转换为DDP模型,并指定每个进程运行的GPU设备。这样可以实现分布式的数据并行训练。
x.3.6 BN在设备间通信
关于BN在设备间通信,便是将BatchNorm层转换为SyncBatchNorm层,代码如下:
resnet_trainer.net = torch.nn.SyncBatchNorm.convert_sync_batchnorm(resnet_trainer.net).to(device)
这段代码的作用是将模型中的BatchNorm层转换为SyncBatchNorm层,并将模型移动到指定的设备上。
torch.nn.SyncBatchNorm.convert_sync_batchnorm是一个用于将BatchNorm层转换为SyncBatchNorm层的静态方法。SyncBatchNorm是在分布式训练中使用的一种归一化层,能够处理不同GPU设备之间的批归一化同步问题。
在这段代码中,resnet_trainer.net是一个模型对象,通过调用torch.nn.SyncBatchNorm.convert_sync_batchnorm(resnet_trainer.net),将模型中的BatchNorm层转换为SyncBatchNorm层。
接下来,使用.to(device)将模型移动到指定的设备上。device是一个指定的设备对象,可以是CPU或GPU设备。
综上所述,这段代码的作用是将模型中的BatchNorm层转换为SyncBatchNorm层,并将模型移动到指定的设备上,以便在分布式训练中使用SyncBatchNorm进行同步归一化操作。
x.3.7 训练
训练的时候需要注意:
- 使用
train_sampler.set_epoch(epoch)来设置采样器的epoch的方法,确保在每个epoch中使用不同的数据采样顺序。即确保每个进程获取到的样本顺序是随机的,避免数据顺序的重复性. - 为了得到更准确的值可以使用
dist.all_reduce(loss)来求取每个GPU加和的平均loss。 - 在rank==0的时候打印信息,存储模型参数。
dist.destroy_process_group()用于清理由DDP引擎创建的临时文件和进程组。
train_sampler.set_epoch(epoch)和dist.destroy_process_group()可参考x.4.6 set_epoch和cleanup()分别是什么意思。
x.4 杂鱼碎碎念
x.4.1 如何查看model/net/模型在哪个GPU上
查看模型在哪个GPU上
model = model.cuda()#将模型转移到gpu上
print(next(model.parameters()).device) # 输出:cuda:0
model = model.cpu()#将模型转移到cpu上
print(next(model.parameters()).device) # 输出:cpu
查看tensor所在位置
data = data.cuda()#将数据转移到gpu上
print(data.device) # 输出:cuda:0
data = data.cpu()#将数据转移到cpu上
print(data.device) # 输出:cpu
x.4.2 ddp中的dist_url是指什么,通常指定为什么,例子
dist_url是指分布式训练过程中用于建立进程间通信的URL。它通常用于指定分布式训练的后端,例如TCP、文件系统等。
具体来说,dist_url是一个包含通信协议和地址的字符串。通常情况下,它由两部分组成:通信后端和地址。通信后端定义了用于进程间通信的具体实现,例如tcp://、file://等。地址部分指定了通信的目标位置,可以是主机名、IP地址或者文件系统路径等。
以下是一个dist_url的示例:
tcp://127.0.0.1:1234:使用TCP协议在本地主机上的端口1234进行通信。file:///path/to/socket:使用文件系统中的Unix socket进行通信,路径为/path/to/socket。
在实际使用中,你可以根据具体的分布式训练设置和要求来指定dist_url。例如,如果你希望在多台主机上进行分布式训练,可以使用基于TCP的通信后端,并指定各个主机的IP地址和端口号作为地址部分。
需要注意的是,dist_url的具体形式和使用方式可能因不同的深度学习框架或分布式训练库而有所差异。因此,你在实际使用时最好参考相应框架或库的文档以了解具体的指定方式和示例。
x.4.3 ddp中的dist_backend是指什么,通常指定为什么,例子
在DDP(分布式数据并行)中,dist_backend是指用于执行分布式训练的后端实现。它定义了在分布式训练期间如何进行进程间通信和同步。
通常情况下,dist_backend的取值是根据使用的深度学习框架或分布式训练库来指定的。不同的框架或库可能提供了不同的后端实现,以适应不同的硬件和网络环境。
以下是一些常见的dist_backend及其示例:
- nccl:这是一个常用的后端实现,用于在NVIDIA GPU上进行高性能的分布式训练。示例:dist_backend=‘nccl’。
- gloo:这是一个通用的后端实现,适用于多种硬件设备和网络环境。示例:dist_backend=‘gloo’。
- mpi:这是基于MPI(Message Passing Interface)的后端实现,适用于在具有MPI支持的集群上进行分布式训练。示例:dist_backend=‘mpi’。
要选择适当的dist_backend,你需要考虑你的硬件设备(如GPU)、网络环境以及框架或库的支持情况。通常,建议根据你的具体设置和需求进行选择。在大多数情况下,nccl和gloo是常见且广泛支持的选择。
需要注意的是,dist_backend的可用选项可能因深度学习框架、分布式训练库和环境配置而有所差异。在实际使用时,最好参考相应框架或库的文档以了解可用的后端选项和如何指定它们。
x.4.4 在DDP中为何要使用model.module.state_dict()保存模型参数
问: 在DDP中为何要使用model.module.state_dict()来存储模型,和直接使用model.state_dict()有什么区别
答:
在DDP(分布式数据并行)中,使用model.module.state_dict()来存储模型的参数状态字典,而不是直接使用model.state_dict(),是因为在分布式训练中,model对象通常被封装在nn.DataParallel或nn.parallel.DistributedDataParallel中。
当使用nn.DataParallel或nn.parallel.DistributedDataParallel包装模型时,模型的实际参数被封装在model.module中,而model本身则是一个包装器对象。这是因为这些并行模型包装器将模型复制到多个设备或进程上进行并行计算,从而加快训练速度。
因此,在存储模型参数状态字典时,应使用model.module.state_dict()而不是model.state_dict()。使用model.module.state_dict()可以确保只存储模型实际的参数,而忽略并行模型包装器本身的状态。
简而言之,区别在于:
- model.state_dict()会返回包含模型及其包装器状态的字典。
- model.module.state_dict()会返回仅包含模型实际参数状态的字典,而忽略并行模型包装器的状态。
在DDP中,为了避免保存模型时包含并行模型包装器的状态,推荐使用model.module.state_dict()来保存模型参数状态字典。
问: 若在DDP时候使用model.state_dict()保存模型参数,再使用单GPU训练使载入参数会存在冲突吗
答:
如果在使用DDP时使用了model.state_dict()保存模型参数,并尝试在单GPU训练中加载这些参数,可能会导致冲突。
当使用DDP进行分布式训练时,model.state_dict()将包含模型及其并行模型包装器的状态,而不仅仅是模型的参数状态。这是因为DDP会复制模型到多个设备上进行并行计算,并使用并行模型包装器管理这些副本。
在单GPU训练中,如果尝试使用model.state_dict()加载具有并行模型包装器状态的参数字典,可能会导致冲突,因为单GPU训练不需要并行模型包装器。这可能会导致加载的参数无法与单GPU模型兼容,导致错误或不准确的行为。
因此,当从DDP转换到单GPU训练时,建议使用model.module.state_dict()来保存和加载模型参数。这样可以确保仅保存和加载模型实际的参数状态,而忽略并行模型包装器的状态,避免潜在的冲突和错误。
x.4.5 DistributedSampler和BatchSampler搭配使用
BatchSampler往往和DistributedSampler搭配使用,但是单单使用DistributedSampler也是完全可以的。
在DDP中,并不一定必须使用BatchSampler。BatchSampler用于定义如何将样本索引划分为批次,它通常与DistributedSampler一起使用,以确保每个进程都处理自己分配的样本。
在分布式数据并行训练中,使用DistributedSampler可以确保每个进程在训练过程中只处理自己负责的样本,避免数据重复或不完整的情况。而BatchSampler用于进一步划分样本索引为批次,以便进行批量训练。
但是,如果你希望在DDP中不使用BatchSampler,也是可以的。在这种情况下,你可以直接使用默认的DataLoader来加载数据集,它会将样本索引划分为大小为batch_size的批次。
以下是一个示例:
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=args.batch_size, sampler=train_sampler)
for inputs, labels in train_loader:
# 在DDP中进行训练
...
这里,DistributedSampler用于确保每个进程只处理自己分配的样本,而DataLoader使用默认的batch_size参数划分样本索引为批次。
总之,使用BatchSampler是一种更灵活的方式,可以更精细地控制样本的划分和批次大小。但在DDP中,并不强制要求必须使用BatchSampler,你也可以直接使用默认的DataLoader来加载数据集。
x.4.6 set_epoch和cleanup()分别是什么意思
set_epoch(epoch)和cleanup()是在使用分布式数据并行(DDP)时,用于设置采样器的epoch和进行清理的函数。
-
set_epoch(epoch): 这是用于设置采样器的epoch的方法。在分布式训练中,每个进程可能负责处理数据集的不同部分。为了确保每个进程在每个epoch中都使用不同的数据采样顺序,需要在每个epoch开始时调用set_epoch(epoch)来设置采样器的epoch值。这样可以保证每个进程获取到的样本顺序是随机的,避免数据顺序的重复性。在代码中,train_sampler.set_epoch(epoch)用于设置训练数据集的采样器的epoch值。
-
cleanup(): 这是用于进行清理操作的方法。在使用DDP进行分布式训练时,每个进程会创建一些临时文件和进程组。在训练结束后,为了清除这些临时文件和进程组,可以调用cleanup()方法进行清理。在代码中,trainer.multi_train_utils.distributed_utils.cleanup()用于清理由DDP引擎创建的临时文件和进程组。
这两个方法在DDP训练中都起着辅助作用。set_epoch()用于确保每个进程在每个epoch中使用不同的数据采样顺序,提高训练的随机性。cleanup()用于在训练结束后清理临时文件和进程组,保持代码的整洁性和资源的释放。
x.4.7 launch的启动代码
python -m torch.distributed.launch --nproc_per_node=6 --use_env /home/yingmuzhi/_learning/pytorch/_ddp/train_multi_GPU/train_multi_gpu_using_launch.py
x.5 DDP代码
代码可见github代码链接:https://github.com/yingmuzhi/ddp
也可见如下,所见及所得,可直接运行:
datautils.py:
import torch
from torch.utils.data import Dataset
class MyTrainDataset(Dataset):
def __init__(self, size):
self.size = size
self.data = [(torch.rand(20), torch.rand(1)) for _ in range(size)]
def __len__(self):
return self.size
def __getitem__(self, index):
return self.data[index]
multi_gpu.py:
import torch
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from datautils import MyTrainDataset
import torch.multiprocessing as mp
from torch.utils.data.distributed import DistributedSampler
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.distributed import init_process_group, destroy_process_group
import os
def ddp_setup(rank, world_size):
"""
Args:
rank: Unique identifier of each process
world_size: Total number of processes
"""
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = "12355"
init_process_group(backend="nccl", rank=rank, world_size=world_size)
class Trainer:
def __init__(
self,
model: torch.nn.Module,
train_data: DataLoader,
optimizer: torch.optim.Optimizer,
gpu_id: int,
save_every: int,
) -> None:
self.gpu_id = gpu_id
self.model = model.to(gpu_id)
self.train_data = train_data
self.optimizer = optimizer
self.save_every = save_every
self.model = DDP(model, device_ids=[gpu_id]) # --- modify
def _run_batch(self, source, targets):
self.optimizer.zero_grad()
output = self.model(source)
loss = F.cross_entropy(output, targets)
loss.backward()
self.optimizer.step()
def _run_epoch(self, epoch):
b_sz = len(next(iter(self.train_data))[0])
print(f"[GPU{self.gpu_id}] Epoch {epoch} | Batchsize: {b_sz} | Steps: {len(self.train_data)}")
self.train_data.sampler.set_epoch(epoch)
for source, targets in self.train_data:
source = source.to(self.gpu_id)
targets = targets.to(self.gpu_id)
self._run_batch(source, targets)
def _save_checkpoint(self, epoch):
ckp = self.model.module.state_dict()
PATH = "/home/yingmuzhi/_learning/src/weights/checkpoint_multi.pt"
torch.save(ckp, PATH)
print(f"Epoch {epoch} | Training checkpoint saved at {PATH}")
def train(self, max_epochs: int):
for epoch in range(max_epochs):
self._run_epoch(epoch)
if self.gpu_id == 0 and epoch % self.save_every == 0: # --- modify
self._save_checkpoint(epoch)
def load_train_objs():
train_set = MyTrainDataset(2048) # load your dataset
model = torch.nn.Linear(20, 1) # load your model
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
return train_set, model, optimizer
def prepare_dataloader(dataset: Dataset, batch_size: int):
return DataLoader(
dataset,
batch_size=batch_size,
pin_memory=True,
shuffle=False,
sampler=DistributedSampler(dataset) # --- modify
)
def main(rank: int, world_size: int, save_every: int, total_epochs: int, batch_size: int):
ddp_setup(rank, world_size) # --- modify
dataset, model, optimizer = load_train_objs()
train_data = prepare_dataloader(dataset, batch_size) # --- modify
trainer = Trainer(model, train_data, optimizer, rank, save_every) # --- modify
trainer.train(total_epochs) # --- modify
destroy_process_group()
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(description='simple distributed training job')
# parser.add_argument('total_epochs', default=50,
# type=int, help='Total epochs to train the model')
# parser.add_argument('save_every', default=10,
# type=int, help='How often to save a snapshot')
parser.add_argument('--total_epochs', default=50,
required=False, type=int, help='Total epochs to train the model')
parser.add_argument('--save_every', default=10,
required=False, type=int, help='How often to save a snapshot')
parser.add_argument('--batch_size', default=32, type=int, help='Input batch size on each device (default: 32)')
args = parser.parse_args()
world_size = torch.cuda.device_count()
mp.spawn(main, args=(world_size, args.save_every, args.total_epochs, args.batch_size), nprocs=world_size)