文章目录
- IP与端口号
- TCP/UDP协议
- 网络字节流
- socket套接字接口
- 总结
IP与端口号
- IP
每台主机都有自己的IP地址,所以当数据从一台主机传输到另一台主机就需要IP地址。报头中就会包含源IP和目的IP
源IP地址:发送数据报那个主机的IP地址,目的IP地址:想发送到的那个主机的IP地址
我们把数据从一台主机传递到另一台主机不是真正目的,真正通信的不是这两个机器,其实是这两台机器上面的软件
应用层不止一个软件。公网IP标识了一台唯一的主机,那么数据就可以由一台主机传递到另一台主机。但是有这么多的软件(进程),怎么保证软件A发送的被软件B接收呢?也就是说用什么来标识主机上客户或者服务进程的唯一性呢?
为了更好的表示一台主机上服务进程的唯一性,用端口号port标识服务进程、客户端进程的唯一性。
- 端口号
端口号是一个2字节16位的整数
端口号用来标识一个进程,告诉操作系统要把数据交给哪一个进程
一个端口号只能被一个进程占用(同一个主机)
由上面可以知道:
IP地址(标识主机全网唯一主机)+ 端口号(标识服务器上唯一的进程)能够标识网络上的某一台主机的某一个进程(全网唯一进程)网络通信的本质就是进程间通信。而我们之前说过进程间通信的本质是看到同一份资源,现在这个资源就是网络
通信的本质就是IO,因为我们上网的行为就两种情况:1.把数据发送出去 2.接收到数据。
标识一个进程有pid,那么为什么还需要端口号port呢?
解耦:首先pid是系统规定的,而port是网络规定的,这样就可以把系统和网络解耦。
port标识服务器的唯一性不能做任何改变,要让客户端能找到服务器,就像110,120样不能被改变。而每次启动进程pid就会改变。
不是所有的进程都需要提供网络服务或请求(不需要port),但每个进程都需要pid。
一个端口号只能被一个进程占用,但是一个进程可以绑定多个端口号
底层OS如何根据port找到指定的进程——uint16(端口号)——task_struct——哈希
我们在网络通信的过程中,IP+port标识唯一性,IP有源IP和目的IP,port也有源端口号和目的端口号。所以我们在发送数据的时候也要把自己的IP和端口号发送过去,因为数据还要被发送回来。所以发送数据的时候一定会多出一部分数据(以协议的形式呈现)
TCP/UDP协议
我们用的套接字接口一定会使用传输层协议,不会绕过传输层去调用下面的协议。而传输层的协议分为TCP协议和UDP协议
- TCP协议
TCP(Transmission Control Protocol 传输控制协议) 特点:
传输层协议
有连接(正式通信前要先建立连接)
可靠传输(在内部帮我们做可靠传输工作)
面向字节流
UDP(User Datagram Protocol 用户数据报协议) 特点:
传输层协议
无连接
不可靠传输
面向数据报
注意:
理解不可靠传输:如发送数据时出现了丢包的情况、或者数据被重复传递了(传递了多份)、或者网络出现了问题等等造成的后果就叫做不可靠。所以传输层就是用来解决可靠性的一个协议。
可不可靠是一个中性词。可靠是需要成本的,往往在维护和编码上都比较复杂;而不可靠没有成本,使用起来也简单。所以要分场景使用。
网络字节流
我们知道内存中的多字节数据相对于内存地址有大端和小端之分。
小端:低权值的数放入低地址。(低低低)
大端:低权值的数放入高地址。
现在就出现一种情况:可能一个大端机用大端的方式发送数据到一个小端机。如果现在跨网络我们也不知道数据到底是大端和小端:
所以就有了规定:
网络中的数据都是大端。发送数据的主机如果是大端机就不用管,如果是小端机就把小端转成大端再发送。接收数据同理
如何定义网络数据流的地址:
发送主机把发送缓冲区中的数据
按内存地址从低到高的顺序发出
接收主机把从网络上接到的字节依次保存在接收缓冲区中,也是按内存地址从低到高的顺序保存也就是说先发出的数据是低地址,后发出的数据是高地址
TCP/IP协议规定,网络数据流应采用大端字节序,即低地址高字节 不管这台主机是大端机还是小端机, 都会按照这个TCP/IP规定的网络字节序来发送/接收数据;如果当前发送主机是小端, 就需要先将数据转成大端; 否则就忽略, 直接发送即可
把数据转化成大端的工作可不需要我们自己来做,那太麻烦了,可以调用库函数做网络字节序和主机字节序的转换即可:
#include <arpa/inet.h>
// 主机序列转网络序列
uint16_t htons(uint16_t hostshort);
uint32_t htonl(uint32_t hostlong);
// 网络序列转主机序列
uint16_t ntohs(uint16_t netshort);
uint32_t ntohl(uint32_t netlong);
**h表示host,n表示network,l表示32位长整数,s表示16位短整数。**主机是大端还是小端在函数内部会自己进行判断。
如果主机是小端字节序,这些函数将参数做相应的大小端转换然后返回。
如果主机是大端字节序,这些函数不做转换,将参数原封不动地返回。
如果是其他数据类型呢?不用担心,未来网络发送的时候所有数据都是字符串;发送数据时使用的原生接口对于字符串信息自动转化
socket套接字接口
- socket常见API
// 创建 socket 文件描述符 (TCP/UDP, 客户端 + 服务器)
int socket(int domain, int type, int protocol);
// 绑定端口号 (TCP/UDP, 服务器)
int bind(int socket, const struct sockaddr *address,socklen_t address_len);
// 开始监听socket (TCP, 服务器)
int listen(int socket, int backlog);
// 接收请求 (TCP, 服务器)
int accept(int socket, struct sockaddr* address,socklen_t* address_len);
// 建立连接 (TCP, 客户端)
int connect(int sockfd, const struct sockaddr *addr,socklen_t addrlen);
IP地址+端口号能够标识该主机上的唯一的一个进程:ip和端口号port就叫为套接字,socket就是插座的意思,未来进行网络通信时,插头和插座配套使用。
函数参数里面有个叫sockaddr的结构体类型,这个我们需要了解一下👇
- sockaddr的结构体
套接字种类是比较多的。常见的有三种:
1.网络套接字
2.原始套接字
3.unix域间套接字
我们主要了解第一个网络套接字
网络套接字主要运用于跨主机之间的通信,也能支持本地通信,而域间套接字只能在本地通信。而原始套接字可以跨过传输层(TCP/IP协议)访问底层的数据。这些套接字应用场景完全不同,所以我们想用就得用三套不同的接口。而为了方便,设计者只设计了一套接口,就可以通过不同的参数,解决所有网络或者其他场景下的通信问题。
这里举两个具体的套接字类型:sockaddr_in(inet,网络通信)与sockaddr_un(unix,域间套接)
struct sockaddr_in {
short int sin_family; // 地址族,一般为AF_INET
unsigned short int sin_port; // 端口号,网络字节序
struct in_addr sin_addr; // IP地址
unsigned char sin_zero[8]; // 用于填充,使sizeof(sockaddr_in)等于16
};
struct sockaddr_un {
sa_family_t sun_family; /* AF_UNIX */
char sun_path[108]; /* 带有路径的文件名 */
};//通过同一个文件的路径来让进程看到同一份资源
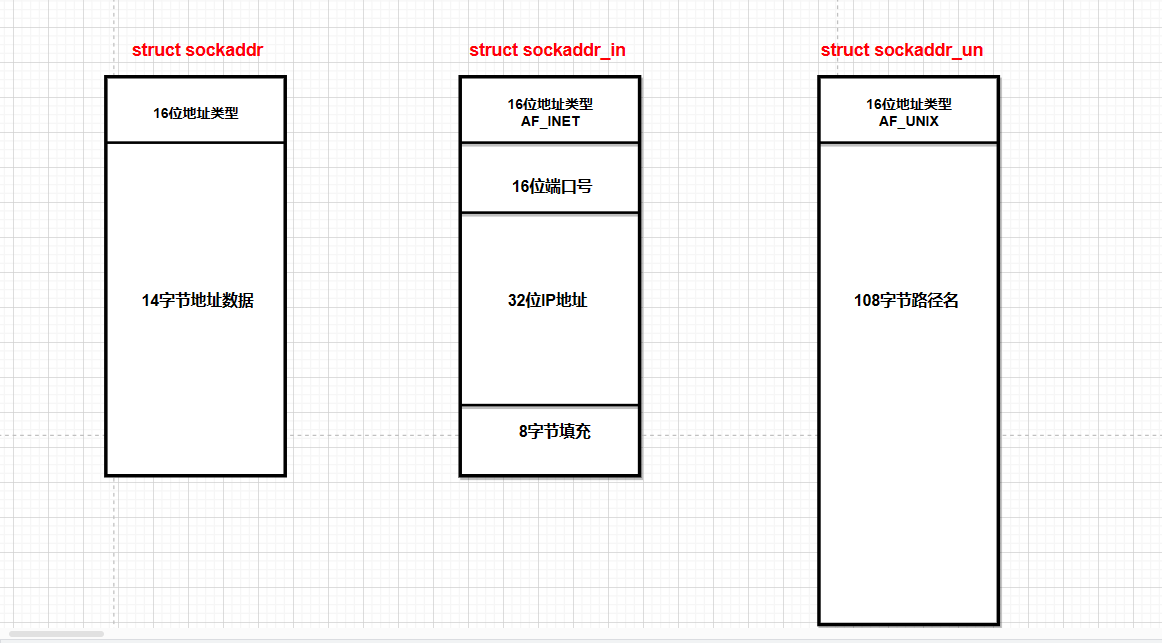
可以看到
sockaddr_in和sockaddr_un是两个不同的通信场景。区分它们就用前2个字节:16地址类型协议家族的标识符(代表是本地通信还是网络通信)。 我们两个结构体都不用,直接用sockaddr。未来进行网络编程时,如果是网络通信,填充的网络信息是struct sockaddr_in这个结构体。
比如说我们想用网络通信,虽然参数是
const struct sockaddr *addr,但实际传递进去的却是sockaddr_in结构体(类型不一样,要强制类型转换)。在函数内部一视同仁,全部看成sockaddr类型,然后根据前两个字节判断到底是什么通信类型然后再强转回去。
接口的设计为什么是structaddr*结构,C语言为了能够接收任意类型是void*,为什么不使用void*,而且void*不用强转因为设计这一批接口时C语言标准还没有void*
这是OS的接口,不可随意更改,其他语言可能不支持void*
所以这就相当于:可以把
sockaddr看成基类,把sockaddr_in和sockaddr_un看成派生类,构成了多态体系
总结
IP地址+端口号port可以标识网络上的某一台主机的某一个进程(全网唯一)
TCP/UDP协议都是传输层的协议,其他特点不同:如UDP是不可靠的
套接字是一种网络通信的机制,IP+端口号port是套接字的形式,网络字节序列规定为大端,规定网络中的数据是大端的。
sockaddr使用统一的接口解决所有网络或者其他场景下的通信问题