动作识别
CANoe
PriorityQueue
wpf
语音识别
elk
双目相机
prometheus
Thread Pool
flume
GPT-3
computed
动态背景
文档管理
支持向量机
网页设计与制作
php送水平台
tensorrt
坑人
领域驱动设计
强化学习 | 课堂笔记 | 第三课 MP的便利性,随机逼近方法







相关文章
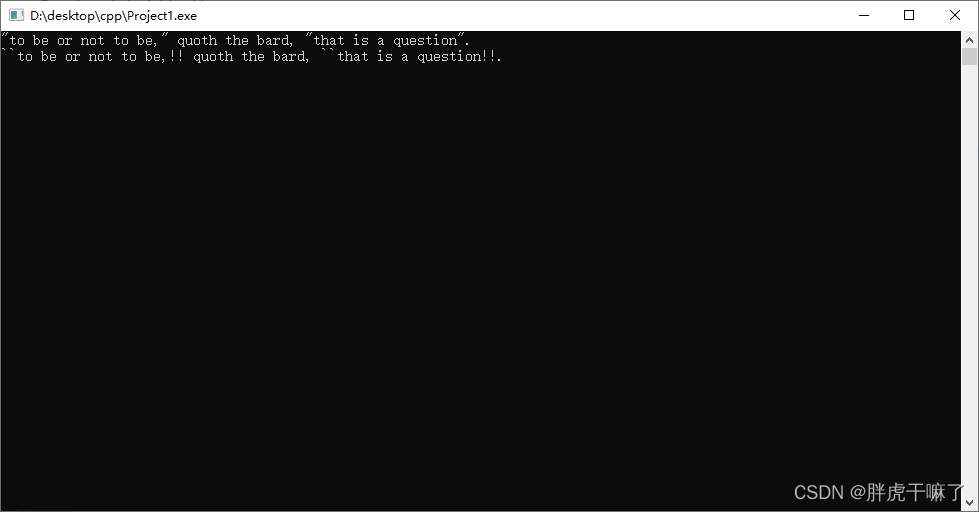
C++从头再来:知识点速通
1. 关于scanf
1.1 读入数字
scanf 的返回值表示成功输入的变量个数,当输入结束时,scanf将无法再次读取数据,返回0
# include <stdio.h>
# include <math.h>
# include <time.h># define M 1000000;
// compute the max,…
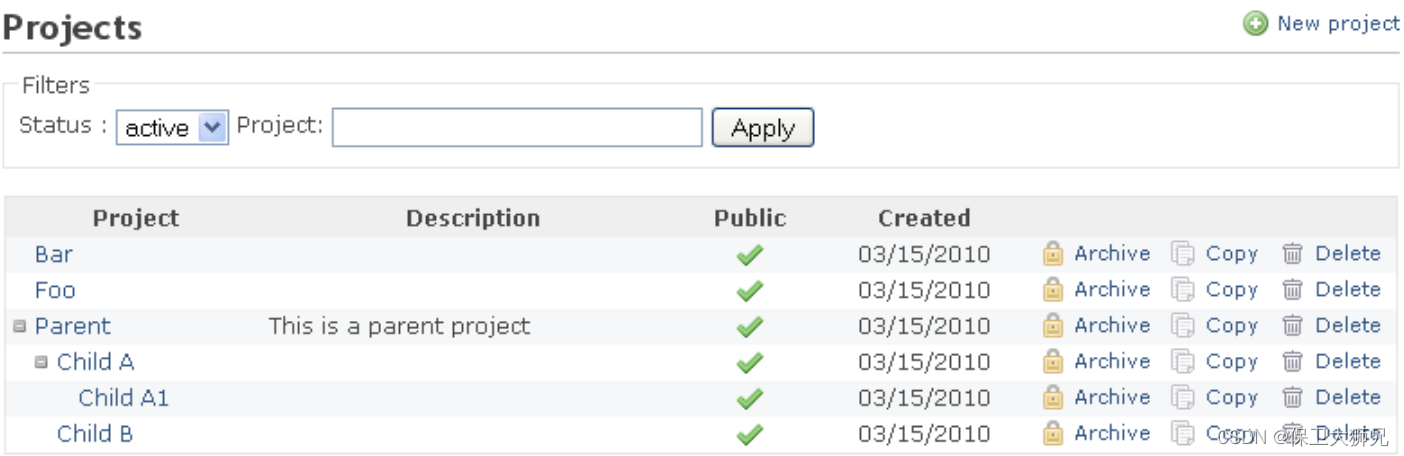
项目管理系统软件有哪些?这10款最好用的项目管理软件值得推荐
项目管理系统软件有哪些?这10款好用的项目管理系统软件值得推荐
如今企业规模不断扩大,业务逐渐复杂化,项目管理系统已经成为现代企业管理中不可或缺的一环;
而项目管理系统软件不仅可以保证项目按时完成,提高团队的…

【Unity】程序集Assembly模块化开发
笔者按:使用Unity版本为2021.3LTS,与其他版本或有异同。请仅做参考 一、简述。 本文是笔者在学习使用Unity引擎的过程中,产学研的一个笔记。由笔者根据官方文档Unity User Manual 2021.3 (LTS)/脚本/Unity 架构/脚本编译/程序集定义相关部分结…

整数反转(python)
题目链接: https://leetcode.cn/problems/reverse-integer/ 题目描述: 给你一个 32 位的有符号整数 x ,返回将 x 中的数字部分反转后的结果。
如果反转后整数超过 32 位的有符号整数的范围 [−231,231−1][−2^{31}, 2^{31} − 1][−231,231…
RTOS中互斥量的原理以及应用
互斥量的原理
RTOS中的互斥量是一种同步机制,用于保护共享资源,防止多个任务同时访问该资源,从而避免数据竞争和不一致性。
互斥量的原理是通过对共享资源进行加锁和解锁操作来实现的。
在RTOS中,互斥量通常是一个数据结构&…
2. 事件捕获 及 如何阻止冒泡
DOM事件流机制 / 事件捕获什么是DOM? DOM 是描述 HTML 的内部数据结构,它会将 Web 页面和 JavaScript 脚本连接起来, 并过滤一些不安全的内容;HTML 解析器会把字节转换成DOM一个事件在发生的时候会在子元素和父元素之间传播,这会分成三个阶段: 1. window 传到目标节点 ---- 捕…

CameraLink备忘录
首先来看看MDR26的引脚定义 从正面看进去,插头端,放置成倒梯形。 上排,从左到右,1到13, 下排,从左到右,14到26.
插座端,是镜像对称关系。 从正面看进去,插座端…

Linux :理解编译的四个阶段
目录一、了解编译二、认识编译的四个阶段(一)预处理(二)编译(三)汇编(四)链接1.静态链接2.动态链接三、分步编译(一)创建.c文件(二)预…